歴史的な毎日の価格から、 4 hour charts of this AUDNZD pair are making lower highs and lower lows and are trading below the 200 SMA as well, we are only looking for opportunities to short the pair…we want to optimize our strategy.

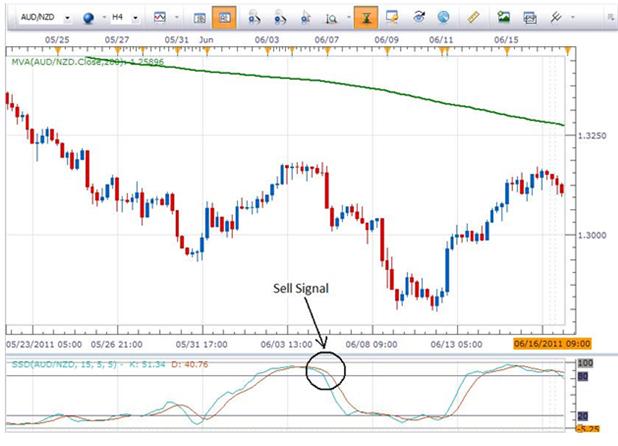
When using Slow Stochastics in a downtrend, as we have on the chart below, the optimum sell signal given by the indicator occurs when the two moving averages comprising the indicator have been above 80 and then move below 80.
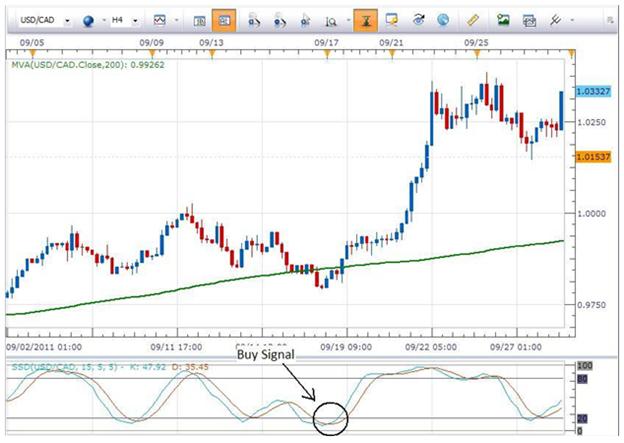
逆に, when using Slow Stochastics in an uptrend, the optimum buy signal given by the indicator occurs when the two moving averages comprising the indicator have been below 20 and then move above 20. This condition can be seen on the historical 4 hour chart of the USDCAD pair below…
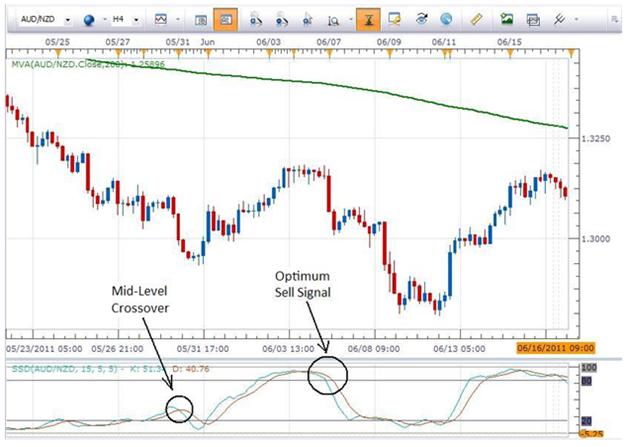
Since the above signals are the optimum signals, not as much attention is paid to the crossovers that occur between the levels of 20 と 80. How should a trader react to those?
しばらくの間 “mid-level” crossovers are valid technical trading signals, 私の意見で, they do not offer as much “pip-potential” as do crossovers occurring at the 80 または 20 レベル.
Allow me to create an analogy…
Think of the lines (moving averages) that comprise Slow Stochastics as a string on a bow that is used to shoot an arrow. The farther that the bowstring is pulled back, the more power it has behind it and the farther the arrow will go. With this in mind, look at the optimum Sell Signal on the chart above and compare it to the Mid-Level Crossover. The crossover that takes place above 80 will have more downside momentum associated with it than will the mid-level crossover that takes place between 20 と 80. The bowstring is not pulled back nearly as far.
While both are valid signals to short the pair, the signal with the most pip potential behind it is the one that had the greater amount of momentum. In this case the pullback to above the 80 level would present the trade with the greater pip potential. While it is not an absolute and will not prove to be true each and every time the condition presents itself, it does represent a “trading edge” that I believe is worth taking.
For the above reason, I generally do not take mid-level crossovers as entry signals in my own trading. むしろ, I exercise patience and discipline and wait for the higher probability signal to set up.
良い取引,
リチャード ・ Krivo
RKrivoFX@gmail.com
@RKrivoFX
